Using Spark and PySpark
Contents
Using Spark and PySpark¶
The Problem with Pandas¶
Lots of data scientists like to use Pandas for building and manipulating huge Datasets and this for good reason, its syntax is easy to pick up and it performs reasonably well. Due to its implementation is has one big draw back: Every DataFrame which is opened will be loaded directly into the Computers Memory.
This is mostly difficult when working when working with huge Datasets, because it requires a huge amout of RAM. This problem can lead to general instability when running ML Pipelines.
What is the advantage of using Spark?¶
On to the stage comes Spark, built with distributed computing at its heart it seems like the perfect fit to manipulate huge datasets.
The architecture of Spark consists of a Spark Executor, a central Cluster Manager and distributed computing nodes - so called Workers. As can be seens on the architecture overview below:
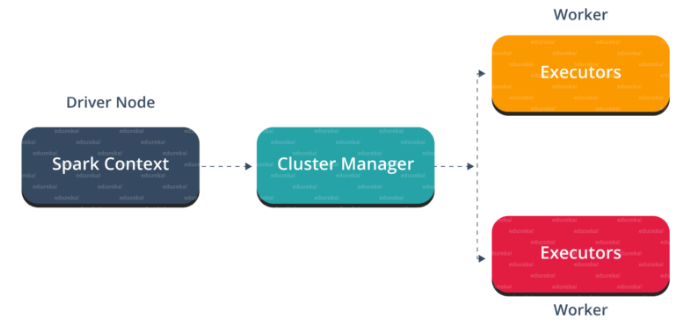
In our relevant Use-Case we had more than 800.000 rows in our Data Frame and since Delta Lake is fully built around the Spark System, we were more or less forced to adapt this into our MLOps Ecosystem.
Another thing very important to note is the Spark Context from with the Jobs run on the cluster get launched. In our case we implemented most of our code in Python, so we needed a Python driver: PySpark.
PySpark¶
PySpark enables one to write python code to run workloads in a Spark cluster. This is definently a time saver, when it comes to MLOps. Most AI pipelines are coded in python anyways and so you dont have to know another language to use Spark. Still I want to point out, that there is a steep learning curve to it. When debugging commands in PySpark some minimal knowledge of Java is helpful.
We will describe how to Setup Spark in combination with Delta-Lake in the next Chapter.